Insights
June 2021
Is That Relevant?

People learn from experience and extrapolate from the relevant past to predict the future. Data-driven regression models do the same thing. To know why, we need to shift our perspective on data.
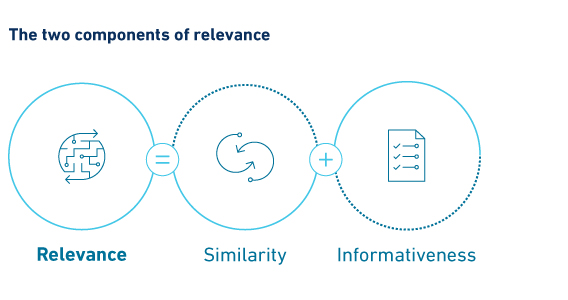
Modern statistics focus on variables: carefully selecting the right ones, measuring their impact and testing their significance. But this approach does not align with the experiential way most people think. We show that it’s possible to reinterpret a linear regression model. The prediction it supplies is equivalent to a weighted average of what happened in the past, where the weight on each observation is its relevance. The human and statistical versions of relevance consist of two parts: similarity and informativeness. We often rely on observations that are similar to today and different from the norm. This view allows us to overlay judgement and statistics using the language of events, leading to more intuitive and effective predictions.
Key Highlights:
It might not be obvious, but most of us think about relevance a lot. The way we anticipate cause and effect (for example, like how we expect touching a hot stove will burn us) is based on piecing together relevant experiences from our past. And when we debate nuanced predictions about the future, it is natural to extrapolate from the past: the last time we faced the same circumstances, what actually happened?
This notion of relevance has two parts. First, we base predictions on experiences that were similar to the task at hand. Second, we tend to remember events that were notable or informative. Experiences that occurred when circumstances were similar to today, but different from the norm, are the most relevant.
But why limit ourselves to just our own experience? This is where data comes in. An economic forecast of United States’ inflation, for instance, can learn from inflation in the US’ distant past, or inflation that occurred in other countries. Whether these experiences are relevant, and how much so, can be measured in a rigorous and precise mathematical way.
We show that linear regression, the workhorse of statistics, makes predictions based on relevance too. To see this requires that we completely reorient our perspective. Think of a regression not in terms of the X variables themselves (say, the columns of a spreadsheet), but in terms of the events we observe (the rows of that spreadsheet). The X variables merely define the relevance of each observation to the conditions that we want to predict. Then, the regression’s prediction for Y is nothing more than a relevance-weighted average of what happened to Y in the past.
As in our previous example for people, relevance equals similarity (x vector close to today’s x vector) plus informativeness (x vector different from average). For regression, these are measured using a formula called the Mahalanobis distance.This perspective brings a few benefits. Data-driven models become more intuitive when we can point to tangible events as the source of their predictions. Peoples’ judgement can be enhanced by overlaying a wider range of experience from data, and the fact that calculators do not suffer from many of our ingrained human biases. Regression models can be improved by censoring irrelevant observations that they would otherwise include. From predicting elections to event studies of US Federal Reserve policy shifts, we have found predictions can improve meaningfully as a result.